

Як Pandora в Україні будує комунікацію з клієнтами без власних соціальних мереж
Валерія Русаненко, Chief marketing Officer Pandora, на RAU Workshop Digital Retail 2026 розповіла, як бренд Pandora в Україні комунікує з клієнтами.
Pandora...






 Дарья Златьева
Дарья ЗлатьеваВ “Черную пятницу” 2018 года компания перевыполнила план, но оказалось, что система не выдержала пиковых нагрузок и “легла”. Как удалось решить проблему и что сделали в Comfy, чтобы не допустить повторения.
Ошибки бывают у всех. На RDBExpo-2019 на сессии “Информационная безопасность в ритейле – суровая реальность или паранойя” Сергей Гаврилов, IT-директор Comfy, рассказал о сложном для компании дне – отказе системы в “Черную пятницу” прошлого года, о том, как пережили кризис, какие выводы сделали, и что предприняли, чтобы это не повторялось.
Трафик сайта Comfy в Black Friday-2018 составил 766 500 человек, что на 20% больше запланированного. Покупки через интернет сделали 153 100 клиентов – на 43% больше, чем годом ранее. В этот день компания столкнулась с серьезной проблемой, но смогла ее решить и даже перевыполнить план по продажам. Как именно – рассказал топ-менеджер ритейлера.
IТ-команда Comfy – это 90 специалистов, которые выстраивают и поддерживают IT-инфраструктуру компании, занимаются разработкой программного обеспечения, и решают множество сопутствующих задач. В Black Friday в пиковом режиме работают все: розница, маркетинг, логистика, IT.
Примерно за месяц до Black Friday было проведено тестирование, которое показало, что все процессы в норме. Масштаб бедствия стал понятен только в момент, когда пошли пиковые нагрузки. Можно сравнить цифры:
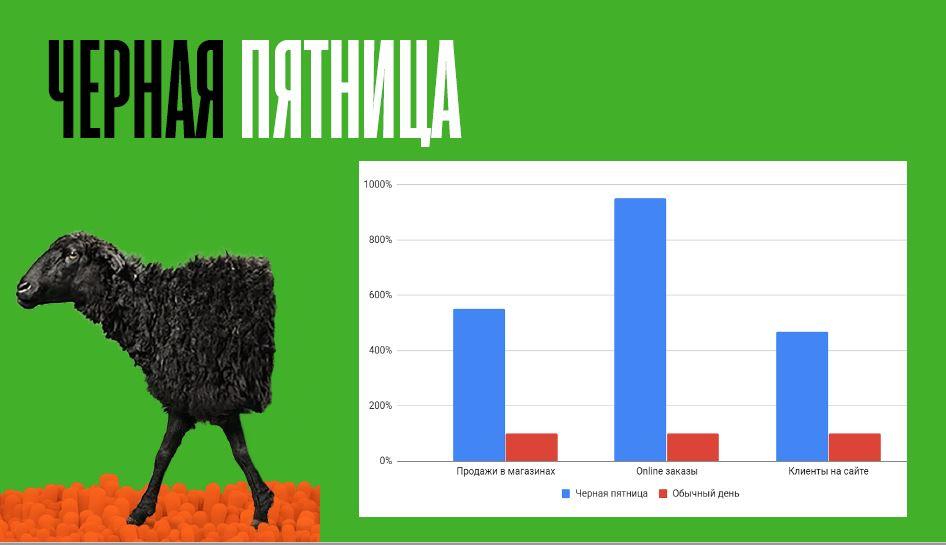
В пик, когда магазины были полны покупателей, система “легла”. На сервера стало приходить аномальное количество “тяжелых” запросов, гораздо больше, чем было в ходе тестирования.
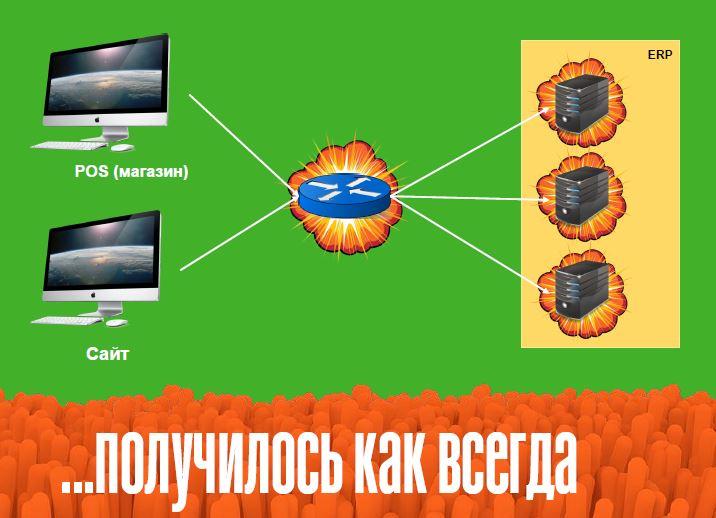
Сервера стали работать в режиме повышенной нагрузки, и отвечать медленно или не отвечать вообще.
У балансера (устройства, разделяющего потоки запросов) была одна особенность, которая ранее казалась нам полезной, потому что работала на повышение качества обслуживания – способность перенаправлять запросы с одного сервера на другой. Она неожиданно породила эффект “снежного кома”: сервер не отвечает на запрос, балансер его перекидывает на другой, тот тоже не отвечает, потом на третий, и так дальше. Все сервера взаимозаменяемые, универсальные, поэтому “под раздачу” попали все. Мало того, когда мы поняли эту ситуацию и попытались запросы “отселить” на выделенные сервера приложений, чтобы хотя бы остальные обрабатывались, то этот балансер тоже стал слабой точкой, потому что на нем образовалась очередь и запросы просто не могли в эту очередь пробиться.
Первопричину поняли достаточно быстро – ей оказался модуль, отвечавший за все акции, скидки, активности, которые предлагают в магазинах. Было принято спасительное решение – отключить интерфейс подбора акций.
Что мы сделали:
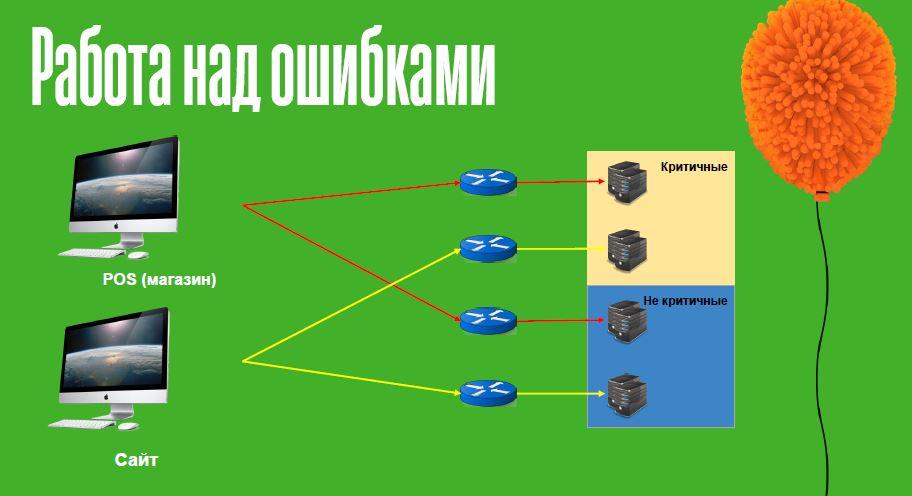 Логика была следующая: есть запросы, потеря любого из которых приводит к остановке продаж: один потерялся и все остальные уже не нужны. Поэтому мы критичные запросы “поселили” на одну группу серверов приложений. А есть запросы, без которых торговать в принципе можно. И чтобы они не помешали критичным, их убрали в другую группу серверов приложений.
Логика была следующая: есть запросы, потеря любого из которых приводит к остановке продаж: один потерялся и все остальные уже не нужны. Поэтому мы критичные запросы “поселили” на одну группу серверов приложений. А есть запросы, без которых торговать в принципе можно. И чтобы они не помешали критичным, их убрали в другую группу серверов приложений.Этим мы максимально отделили друг от друга функциональные блоки, и минимизировали их влияние друг на друга.
Исходя из этого, могу дать несколько советов:
В стремлении к идеалу главное вовремя остановиться: наша “навороченная” логика с переключением запросов между собой, которую мы придумали до события, была излишней. Достаточно было остановиться на проверенном, нормальном паттерне: выбери сервер приложений, отправь на него запрос, не получил ответ – отключи. Максимум к чему это приведет – какому-то количеству пользователей придется лишний раз нажать кнопку, но эффекта “снежного кома” не будет.
И самое главное: какой бы красивой ни казалась архитектура, какими бы утешительными не были результаты нагрузочного тестирования, как бы вы не были уверены, что у вас все хорошо – сбой может “прилететь” с самой неожиданной стороны: это может быть ошибка проектирования, человеческий фактор, забытая косая черта в исходном коде – что угодно. Спрогнозировать это невозможно, поэтому нужен план Б.
По результатам этого сбоя мы проработали планы Б: в основном они сводятся к отключению не очень критичных блоков, снижению нагрузки, к тому, чтобы процесс продаж в случае критической ситуации был не таким комфортным для продавца, но чтобы это хотя бы работало и можно было обслуживать клиентов.
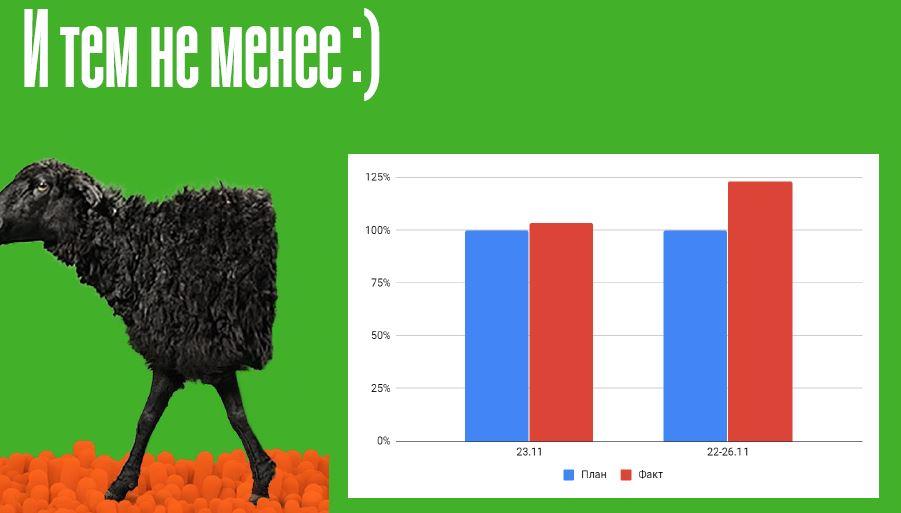
Отмечу, что сотрудники совершили чудо в тот день: они уговаривали клиентов подождать, угощали чаем, убеждали прийти чуть позже и когда в конце концов система “завелась”, ринулись с такой активностью обслуживать клиентов, что план по Black Friday как непосредственно по 23 ноября, так и по всему периоду пиковых продаж, был не просто выполнен, а перевыполнен.
Читайте также –
«Хьюстон, у нас проблемы». Как в Kasta, Multiplex, Zakaz.ua и Comfy выходят из проблемных ситуаций

