У “Чорну п’ятницю” 2018 року компанія перевиконала план, але виявилося, що система не витримала пікових навантажень і “лягла”. Як вдалося вирішити проблему і що зробили в Comfy, щоб не допустити повторення.
Помилки бувають у всіх. На RDBExpo-2019 на сесії “Інформаційна безпека в рітейлі – сувора реальність чи параноя” Сергій Гаврилов, IT-директор Comfy, розповів про складний для компанії день – відмову системи в “Чорну п’ятницю” минулого року, про те, як пережили кризу, які висновки зробили, і що зробили, щоб це не повторювалося.
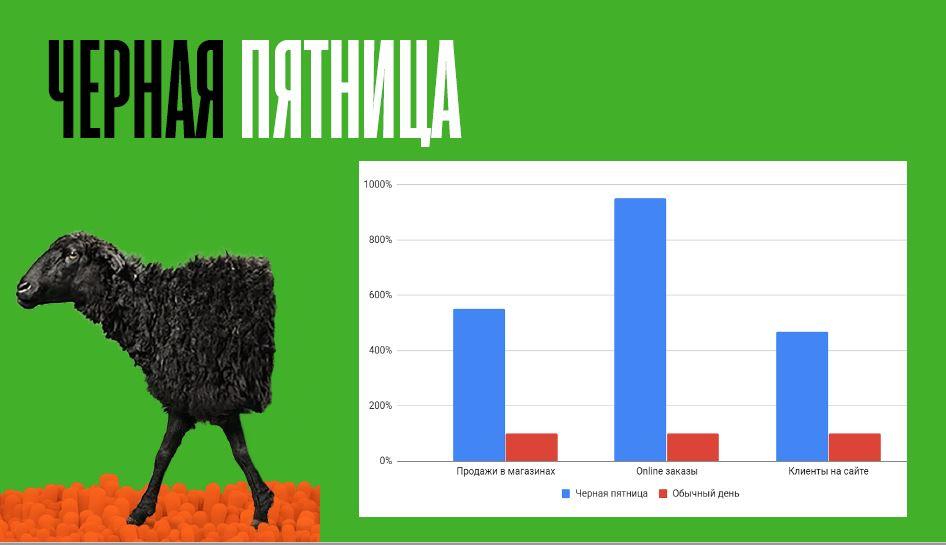
Трафік сайту Comfy в Black Friday-2018 склав 766 500 осіб, що на 20% більше від запланованого. Покупки через інтернет зробили 153 100 клієнтів – на 43% більше, ніж роком раніше. У цей день компанія зіткнулася з серйозною проблемою, але змогла її вирішити і навіть перевиконати план з продажу. Як саме – розповів топ-менеджер рітейлера.
Тести показували “зелене світло”
IТ-команда Comfy – це 90 фахівців, які вибудовують і підтримують IT-інфраструктуру компанії, займаються розробкою програмного забезпечення, і вирішують безліч супутніх завдань. У Black Friday в піковому режимі працюють всі: роздріб, маркетинг, логістика, IT.
Приблизно за місяць до Black Friday було проведено тестування, яке показало, що всі процеси в нормі. Масштаб проблеми став зрозумілий тільки в момент, коли пішли пікові навантаження. Можна порівняти цифри:
У піковий час, коли магазини були повні покупців, система “лягла“. На сервера стала приходити аномальна кількість “важких“ запитів, набагато більше, ніж було в ході тестування.
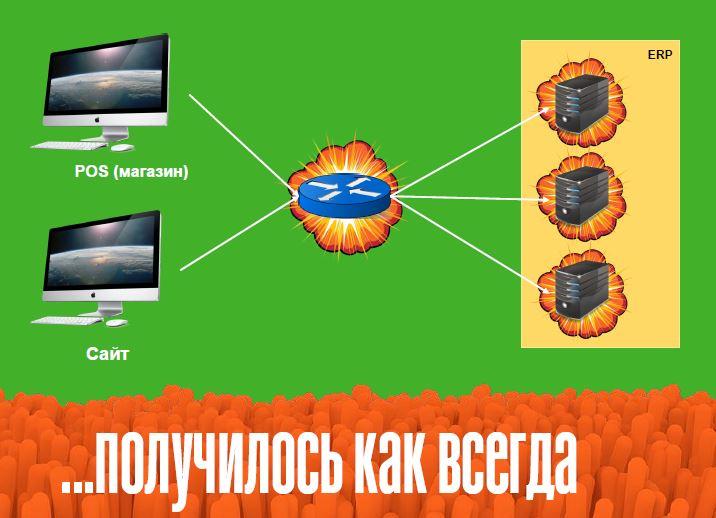 Сервера стали працювати в режимі підвищеного навантаження, і відповідати повільно або не відповідати взагалі. У балансирі (пристрої, що розділяє потоки запитів) була одна особливість, яка раніше здавалася нам корисною, тому що працювала на підвищення якості обслуговування – здатність перенаправляти запити з одного сервера на інший. Вона несподівано породила ефект “снігової кулі”: сервер не відповідає на запит, балансір його перекидає на інший, той теж не відповідає, потім на третій, і так далі. Всі сервера взаємозамінні, універсальні, тому “під роздачу” потрапили всі. Мало того, коли ми зрозуміли цю ситуацію і спробували запити “відселити” на виділені сервери додатків, щоб хоча б інші оброблялися, то цей балансір теж став слабкою точкою, тому що на ньому утворилася черга і запити просто не могли в цю чергу пробитися.
Сервера стали працювати в режимі підвищеного навантаження, і відповідати повільно або не відповідати взагалі. У балансирі (пристрої, що розділяє потоки запитів) була одна особливість, яка раніше здавалася нам корисною, тому що працювала на підвищення якості обслуговування – здатність перенаправляти запити з одного сервера на інший. Вона несподівано породила ефект “снігової кулі”: сервер не відповідає на запит, балансір його перекидає на інший, той теж не відповідає, потім на третій, і так далі. Всі сервера взаємозамінні, універсальні, тому “під роздачу” потрапили всі. Мало того, коли ми зрозуміли цю ситуацію і спробували запити “відселити” на виділені сервери додатків, щоб хоча б інші оброблялися, то цей балансір теж став слабкою точкою, тому що на ньому утворилася черга і запити просто не могли в цю чергу пробитися.
Як боролися
Першопричину зрозуміли досить швидко – нею виявився модуль, який відповідав за все акції, знижки, активності, які пропонують в магазинах. Було прийнято рятівне рішення – відключити інтерфейс підбору акцій.
Що ми зробили:
- Розділили модулі, сервера додатків і зробили для них певну спеціалізацію. В силу певних причин ми не могли ізолювати кожен модуль на своєму сервері додатків – занадто великі накладні витрати. Але як мінімум розділили запити на критичні і не критичні.
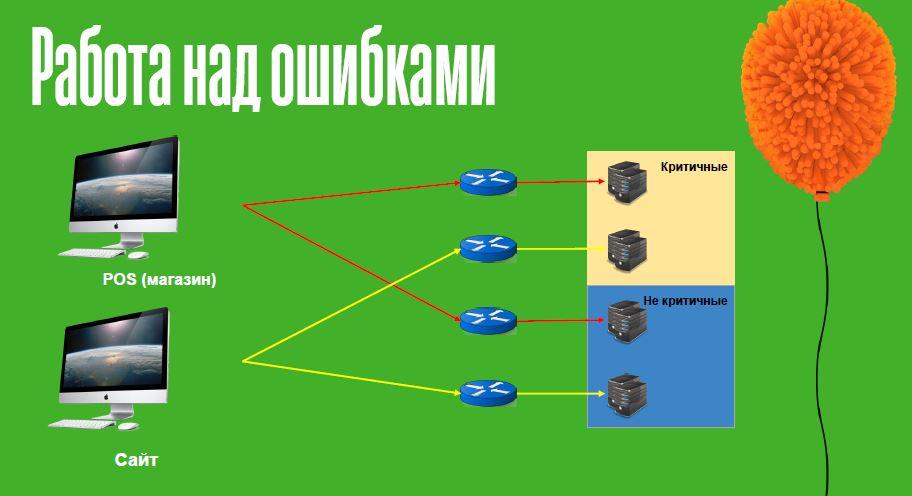 Логіка була така: є запити, втрата будь-якого з яких призводить до зупинки продажів: один загубився і всі інші вже не потрібні. Тому ми критичні запити “поселили” на одну групу серверів додатків. А є запити, без яких торгувати в принципі можна. І щоб вони не завадили критичним, їх включили до іншої групи серверів додатків.
Логіка була така: є запити, втрата будь-якого з яких призводить до зупинки продажів: один загубився і всі інші вже не потрібні. Тому ми критичні запити “поселили” на одну групу серверів додатків. А є запити, без яких торгувати в принципі можна. І щоб вони не завадили критичним, їх включили до іншої групи серверів додатків.
2. Розділили канали, тобто окрему групу серверів додатків зробили під різні канали, щоб інтернет-магазин і фізичний роздріб один на одного не впливали.
3. І останнє: під кожну групу зробили свій балансір, щоб і він не впливав на інші елементи системи.
Цим ми максимально відокремили один від одного функціональні блоки, і мінімізували їх вплив один на одного.
Виходячи з цього, можу дати кілька порад:
- Намагайтеся мінімізувати в своїх системах вплив елементів один на одного – без якогось конкретного блоку інші повинні нормально працювати. Якщо один блок призводить до зупинки всього іншого – система лягає.
- Засоби діагностики розробляйте відразу, щоб мати можливість у критичній ситуації розуміти що відбувається, локалізувати проблему та якомога швидше її усунути.
- У прагненні до ідеалу головне вчасно зупинитися: наша “наворочена” логіка з перемиканням запитів між собою, яку ми придумали до події, була зайвою. Досить було зупинитися на перевіреному, нормальному патерні: вибери сервер додатків, відправ на нього запит, не отримав відповідь – відключи. Максимум до чого це призведе – певній кількості користувачів доведеться зайвий раз натиснути кнопку, але ефекту “снігової кулі” не буде.
І найголовніше: якою б гарною не здавалася архітектура, якими б втішними були результати тестування, як би ви не були впевнені, що у вас все добре – збій може “прилетіти” з найнесподіванішої сторони: це може бути помилка проектування, людський фактор, забута коса риска в вихідному коді – що завгодно. Спрогнозувати це неможливо, тому потрібен план Б.
За результатами цього збою ми пропрацювали плани Б: в основному вони зводяться до відключення не надто критичних блоків, зниження навантаження, до того, щоб процес продажів в разі критичної ситуації був не таким комфортним для продавця, але щоб це хоча б працювало і можна було обслуговувати клієнтів.
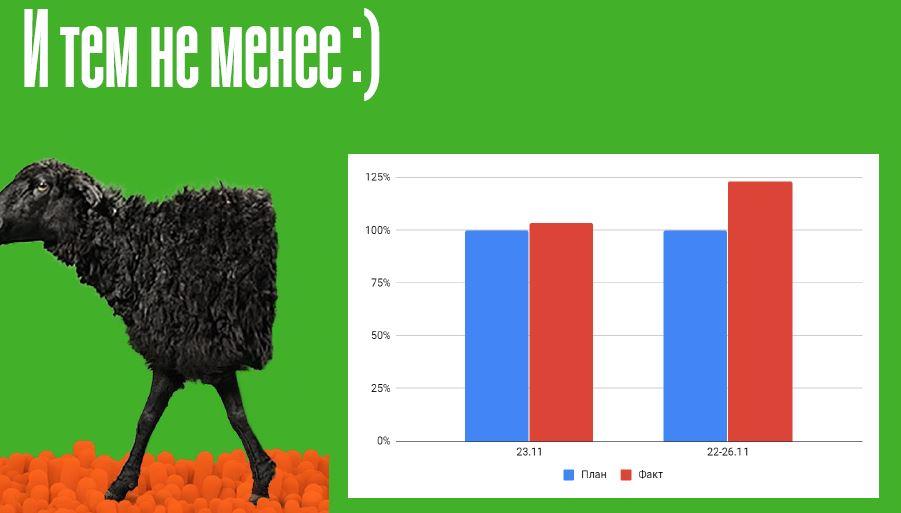
Зазначу, що співробітники зробили диво в той день: вони вмовляли клієнтів почекати, пригощали чаєм, переконували прийти трохи пізніше, а коли врешті-решт система “завелася”, кинулися з такою активністю обслуговувати клієнтів, що план по Black Friday як безпосередньо по 23 листопада, так і по всьому періоду пікових продажів, був не просто виконано, а перевиконано.
Читайте також –
“Х’юстон, у нас проблеми”. Як в Kasta, Multiplex, Zakaz.ua і Comfy виходять з проблемних ситуацій











